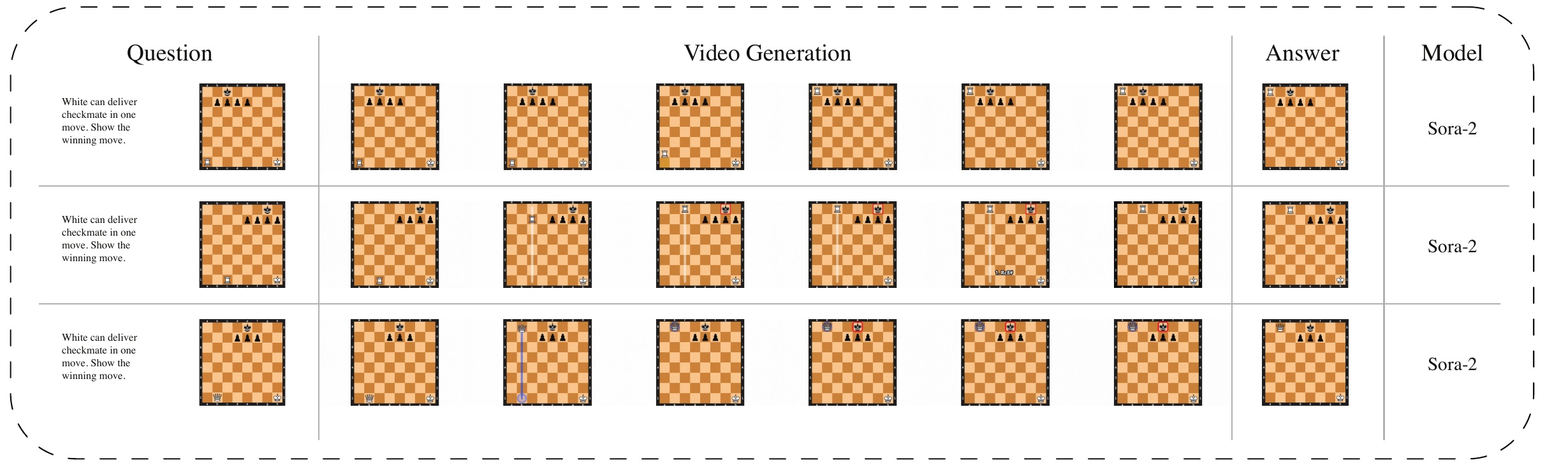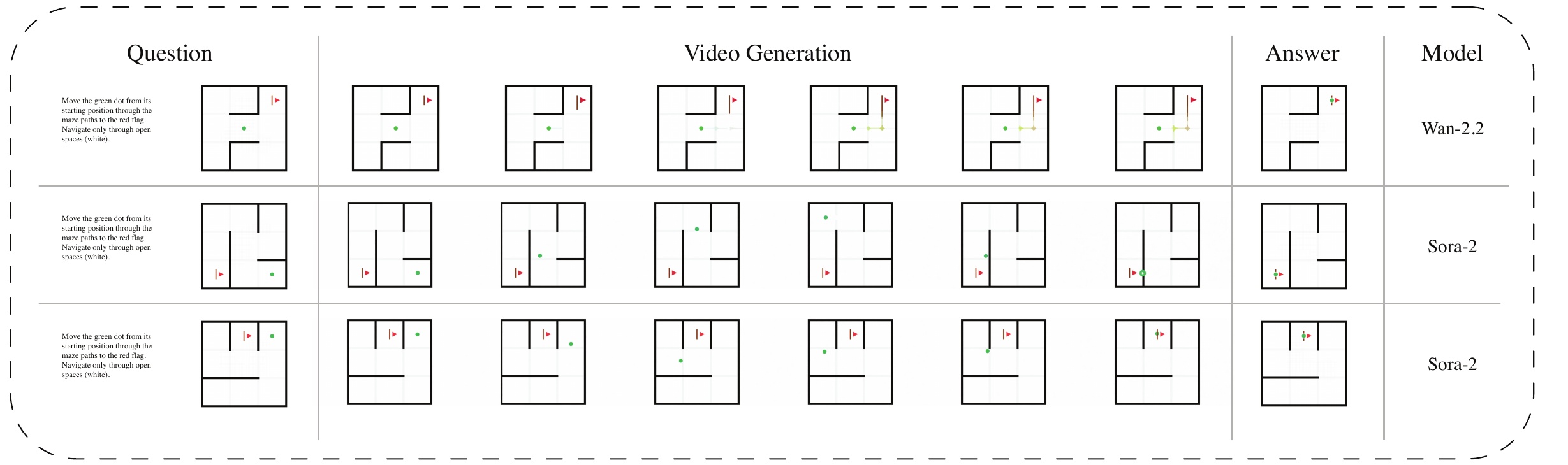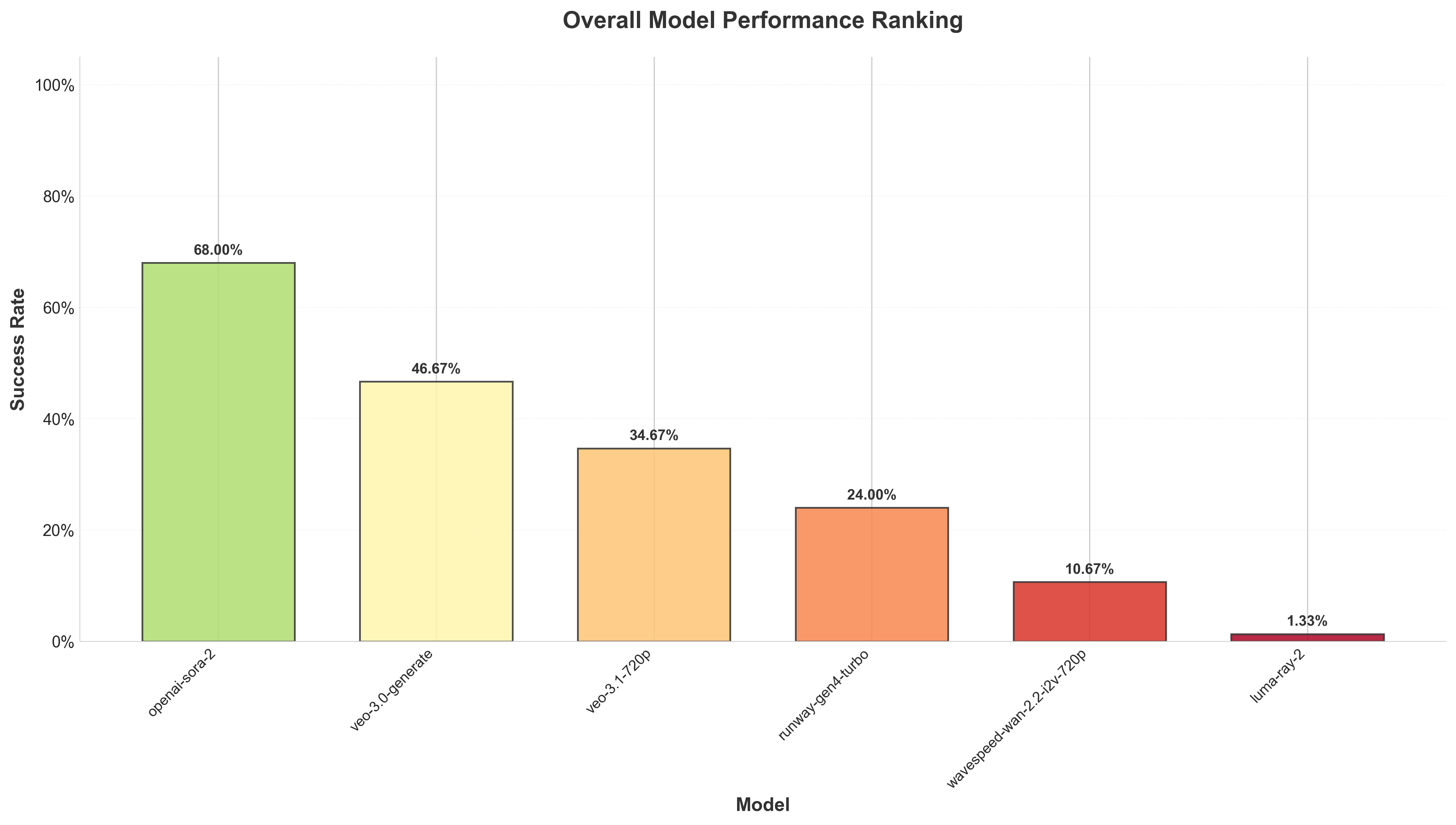
Each Task Pair consists of three core components:
Initial State
first_frame.png
Starting point or problem setup
Final State
final_frame.png
Goal state or expected solution
Text Prompt
prompt.txt
Instructions for video model